Configuring Ops#
In many situations, we'd like to be able to configure ops at run time. For example, we may want whomever is running the job to decide what dataset it operates on. Configuration is useful when you want the person or system that is launching a job to be able to make choices about what the job does, without needing to modify the job definition.
We've seen an op whose behavior is the same every time it runs:
@op
def download_cereals():
response = requests.get("https://docs.dagster.io/assets/cereal.csv")
lines = response.text.split("\n")
return [row for row in csv.DictReader(lines)]
If we want the URL to be determined by whomever is launching the job, we might write a more generic version:
@op
def download_csv(context):
response = requests.get(context.op_config["url"])
lines = response.text.split("\n")
return [row for row in csv.DictReader(lines)]
Here, rather than hard-coding the value of the URL we want to download from, we use a config option, url. In order to access that config option, our decorated function accepts an argument named "context". When Dagster sees an argument named "context", instead of treating it as one of the op's inputs, it provides an instance of OpExecutionContext. A consequence of this is that ops cannot have inputs named "context".
Let's rebuild a job we've seen before, but this time using our newly parameterized op.
import csv
import requests
from dagster import get_dagster_logger, job, op
@op
def download_csv(context):
response = requests.get(context.op_config["url"])
lines = response.text.split("\n")
return [row for row in csv.DictReader(lines)]
@op
def sort_by_calories(cereals):
sorted_cereals = sorted(cereals, key=lambda cereal: int(cereal["calories"]))
get_dagster_logger().info(f'Most caloric cereal: {sorted_cereals[-1]["name"]}')
@job
def configurable_job():
sort_by_calories(download_csv())
Specifying Config for Job Execution#
We can specify config for a job execution regardless of how we execute the job — the Dagit UI, Python API, or the command line:
Dagit Config Editor#
Dagit provides a powerful, schema-aware, typeahead-enabled config editor to enable rapid experimentation with and debugging of parameterized job executions. As always, run:
dagit -f configurable_job.py
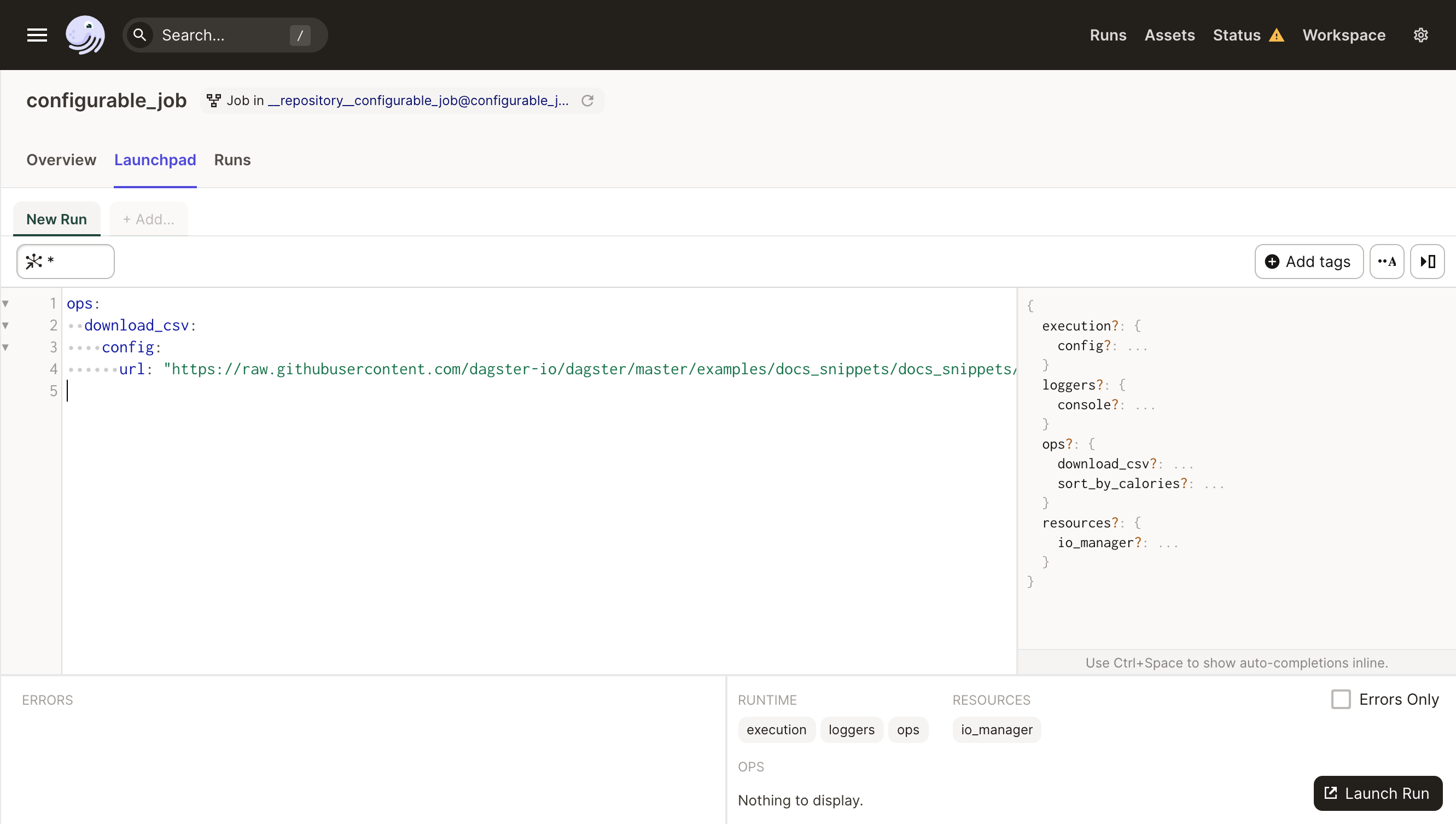
Select the "Launchpad" tab to get to the place for entering config and launching jobs. Here's the config we need to execute our job:
ops:
download_csv:
config:
url: "https://raw.githubusercontent.com/dagster-io/dagster/master/examples/docs_snippets/docs_snippets/intro_tutorial/cereal.csv"
Let's enter it into the config editor:
Config in Python API#
We previously encountered the JobDefinition.execute_in_process function. Job run config is specified by the second argument to this function, which must be a dict.
This dict contains all of the user-provided configuration with which to execute a job. As such, it can have a lot of sections, but we'll only use one of them here: per-op configuration, which is specified under the key ops:
run_config = {
"ops": {
"download_csv": {
"config": {"url": "https://docs.dagster.io/assets/cereal.csv"}
}
}
}
The ops dict is keyed by op name, and each op is configured by a dict that may itself have several sections. In this case, we are interested in the config section.
Now you can pass this run config to JobDefinition.execute_in_process:
result = configurable_job.execute_in_process(run_config=run_config)
YAML fragments and Dagster CLI#
When executing jobs with the Dagster CLI, we'll need to provide the run config in a file. We use YAML for the file-based representation of configuration, but the values are the same as before:
ops:
download_csv:
config:
url: "https://raw.githubusercontent.com/dagster-io/dagster/master/examples/docs_snippets/docs_snippets/intro_tutorial/cereal.csv"
We can pass config files in this format to the Dagster CLI tool with the -c flag.
dagster job execute -f configurable_job.py -c run_config.yaml
In practice, you might have different sections of your run config in different yaml files—if, for instance, some sections change more often (e.g. in test and prod) while other are more static. In this case, you can set multiple instances of the -c flag on CLI invocations, and the CLI tools will assemble the YAML fragments into a single run config.
Putting Schema on a Config#
The implementation of the download_csv op we wrote above expects the provided configuration will look a particular way. I.e. that it will include a key called "url" and an accompanying value that is a string. If someone running the job were to neglect to provide config, the op would fail with a KeyError when it tried to fetch the value for "url" from context.op_config. If the provided value were an integer and not a string, the op would also fail, because requests.get expects a string, not an integer.
Dagster allows specifying a "config schema" on any configurable object to help catch these kinds of errors early. Here's a version of download_csv that includes a config_schema. With this version, if we try to pass config that doesn't match the expected schema, Dagster can tell us immediately.
import csv
import requests
from dagster import op
@op(config_schema={"url": str})
def download_csv(context):
response = requests.get(context.op_config["url"])
lines = response.text.split("\n")
return [row for row in csv.DictReader(lines)]
The ConfigSchema documentation describes all the ways that you can provide config schema, including optional config fields, default values, and collections.
In addition to catching errors early, config schemas are also useful for documenting jobs and learning how to use them. This is particularly useful when launching jobs from inside Dagit.
Because of the config schema we've provided, Dagit knows that this job requires configuration in order to run without errors.
Go back to the Launchpad and press Ctrl + Space in order to bring up the typeahead assistant.
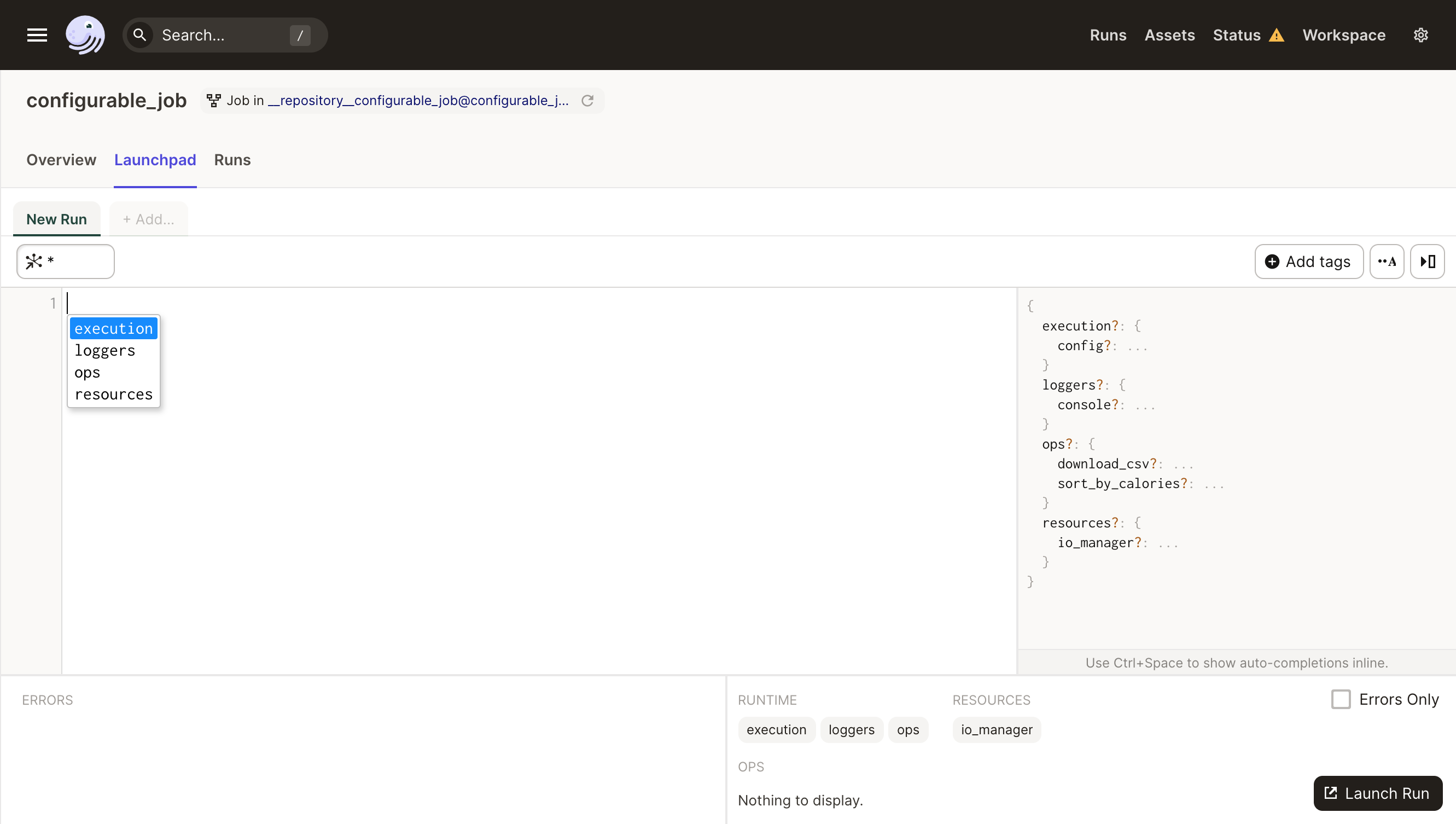
Here you can see all of the valid config fields for your job.